[continued from the previous post, this series of posts is a complete translation of `Philosophy Paper, written by F.A. Waaldijk, student of mathematics, student number 8327661, in the year 1991′]
[—–fifth post in the translation—–]
Chapter one
Wir machen uns Bilder der Welt[1]; why, how?
Why people feel the need to express themselves, to express what goes on in their world, is not entirely clear. Some say that it is because people wish to grasp[2] their experiences, to give themselves more grip on their world. And, so they say, the only way to do so is to condense those experiences, that world, for instance in a stone sculpture, or a painting, or in words. A good painting is a good painting because it is a condensation of what you experience, what you think, what you feel. A condensation which is comprehensible at least, because it leaves out everything which in daily life makes understanding impossible.
For example, who really understands well how a city like Nijmegen functions? Who knows really well what all happens in this city, what patterns, what developments, in the social field, in the economical field, in the technological field, in nature? And how do these fields interrelate? As soon as you try to think about this seriously you start to get dizzy. It is simply too complicated. In practice it boils down to that you occupy yourself with a small piece, and that there are others who occupy themselves with the glueing together of all those small pieces, etc. In this way the city is administered. But nobody understands the totality.
When I bicycle through Nijmegen, it strikes me that I know the town primarily in the following way: I know how I must cycle from one place to another, if I want to do it as fast as possible, or if I want to encounter as little car traffic as possible, or if I want to buy some bread on the way, or… It appears there are a large number of routes in my head, from which I can choose, all according to my mood and my need. It is however not the case that I hold those routes in my head in all detail, I simply know enough to be able to make a decision on each junction, from the Berg en Dalseweg left on the Corduwenerstraat, cross the Hengstdalseweg, go up, go right on the Postweg and then on the corner with the Broerdijk there is a baker whose name I do not mention because ve would not give more than five guilders for this form of advertising, which is laughable.
When I follow such a route in my head, I only ever know small pieces (crossroads, some bends, some hills, etc.) which I glue together. And those small pieces I only know from a cycling and pedestrian perspective, by car my knowledge of Nijmegen is far more limited. Sometimes it is hard to glue those small pieces together well. Suppose I ask you for the shortest way (by bike) from the Waalkade to the Radboud hospital such that you encounter three bakers and three hairdressers (in that sequence) on the way?
Put differently, my knowledge of Nijmegen consists of an enormous collection of (small) maps. When I wish to go from one place to another, I glue a number of these maps together as well as they will allow, for as long as it takes to end up with something that promises to be a good route. But these maps are not always of the same character, some are meant for the bicycle, othes for bus and foot, some indicate the elevation differences, others the probability of flat tires (bottle bank), etcetera, etcetera. And maybe the most important is that these maps are strongly imprecise, they are rough approximations, rough condensations which at least are comprehensible since they leave out almost everything which in the real situation makes comprehension impossible.
When glueing together my small maps it sometimes happens that these imprecisions add up, and that the resulting route is not the right (or the best) one. Sometimes while cycling I find that things are just a little different from what I thought, and that I should have taken the Groesbeeksedwarsweg after all. This then gives me a new small map, which in this situation is more accurate than the small maps I already had, but which in another situation might hinder me again. All in all I would get to know Nijmegen better and better, were it not for the fact that Nijmegen itself also changes. Therefore my maps age, and I have to keep on providing old maps with a stamp `still reasonably valid’ or a stamp `really no longer valid’, and sometimes a stamp `hooray! valid again’. Apart from that, I must also continually make new maps.
You may say, reader, : why don’t you buy a city map, and every five years a new one? Good question. I’m too lazy for it, I suppose. But, so I can state in my defense, for a city map the same thing holds as for my little maps. It remains a rough approximation, a rough condensation, I will always keep encountering surprises. A city map, true to its name [in Dutch: `cityflatground’] does not indicate elevation differences. And it doesn’t tell me either at which baker’s you can buy tasty bread and at which baker’s you can buy tasty almond paste pastries, where to find the prettiest catalpa and where the Japanese cherry in bloom.
After this lengthy introduction I feel strengthened to write down the main thesis of this paper:
main thesis:
The mythos, the sum total of all our knowledge, all our understanding of the world, consists of maps. These maps are small and very divergent in character. Some are rational in nature, some emotional, some differ otherwise. Some are obsolete, some are new, some are fragrant, others visual, some verbal. Some are about spring, others about Wittgenstein. Very importantly, all these maps are imprecise, rough approximations, rough condensations, rough simplifications.
Now what happens if in a certain situation I ask myself the question: how should I behave?, or equivalently: what should I do? This means I’m asking for an acceptable route, preferably a good route, which leads me from today to tomorrow, from this situation to the next. To find that route I consult my maps of the situation in which I happen to be, and I try to glue a number of these small maps together.
This is complicated by the fact that my maps are not only imprecise, and strongly divergent in character, but also often contradictory. In a certain sense it therefore is convenient to not have too many maps at your disposal. Another disadvantage of having many maps, is that at a certain point you occupy yourself exclusively with the maps, and no longer with the world itself. When was the last time, reader, that you took the time to brush your fingers over a pine cone, to look at it, smell it, throw it in the air, play football with it, put it in your mouth to see what it tastes like?
For example, someone offers a dog a lit cigarette. Most likely the dog will reject this offer, trusting on its nose (this stinks) and its fear of fire. A human being of say thirteen summers has a more difficult job of it, vir maps could be somewhat like this: it stinks, it is not allowed by my mom and dad, that’s just what makes it exciting, it’s bad for your lungs, if I refuse I won’t belong, etc. By the time ve has taken a decision, the cigarette has burnt out (well…in a manner of speaking).
[—–to be continued in the next post—–]
1. freely after Wittgenstein ({3}, 1-1.21 ; 2.063-2.12)
2. try to take `grasp’ as literally as you can [translated from the Dutch `begrijpen’ which means `grasp’ and `understand’ at the same time]



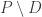




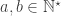
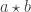



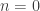




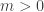

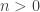

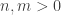


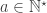

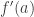









 and
and  be two natural spaces, with corresponding pre-natural spaces
be two natural spaces, with corresponding pre-natural spaces  and
and  . Let
. Let  to
to  Then
Then  -morphism) from
-morphism) from  and all
and all  :
: is in
is in  (`points go to points’)
(`points go to points’) implies
implies  .
.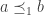 implies
implies 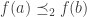 (this is an immediate consequence of (i))
(this is an immediate consequence of (i)) to
to  does not necessarily imply
does not necessarily imply  for
for  for all
for all 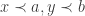 in
in 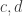 in
in  naturally carry an apartness on dots such that if
naturally carry an apartness on dots such that if 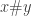 for all
for all 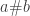 . In this situation, (ii) of the definition becomes equivalent with (ii’):
. In this situation, (ii) of the definition becomes equivalent with (ii’):  is
is 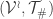 . This means that it always suffices to look at
. This means that it always suffices to look at  .
. be a natural space with corresponding pre-natural spaces
be a natural space with corresponding pre-natural spaces  . Assume
. Assume  is an enumeration of
is an enumeration of 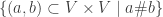 . To create a point
. To create a point  in
in  as
as  . Then, one chooses
. Then, one chooses 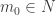 , and for the next
, and for the next 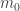 values of
values of  one is free to choose basic dots
one is free to choose basic dots  , but at stage
, but at stage  we must choose for
we must choose for  a basic dot
a basic dot  such that
such that  . Then one chooses
. Then one chooses 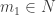 , etc. Therefore we see that, if one disregards the partial order, we did not create any new structure outside of Baire space. And there is no problem whether our point are sets (contrasting to formal topology, where there seems to be a problem in general whether the points of a formal space form a set).
, etc. Therefore we see that, if one disregards the partial order, we did not create any new structure outside of Baire space. And there is no problem whether our point are sets (contrasting to formal topology, where there seems to be a problem in general whether the points of a formal space form a set). 
