
When I was in college (in the ’80s) the question why humans outperform computers in image recognition already was receiving some attention. At the time an idea came to me, and it still seems relevant enough to write down. No doubt similar ideas have been brought forward, but some repetition will do no harm.
In this post I describe a simple conceptual model of how human image recognition could work, given the obvious limitation on human memory capacity when compared to computers. A key observation is that although we are good at passive recognition, our active visual memory seems very limited. We do not seem to store entire images in our memory. If we are asked to visualize objects, faces, scenes in our mind we usually find that it is very hard to really produce `detailed’ mental imagery.
The model also offers an explanation for the déjà vu phenomenon.
Recent developments and background
Nowadays, there are areas of image recognition / classification in which computers outperform humans, so the question has evolved a bit. But still, in the general field of image recognition the feeling is that humans are generally better than computers…so far.
Stanford University (Andrej Karpathy with Fei-Fei Li) in collaboration with Google has recently announced a significant improvement in artificial-intelligence image recognition (New York Times article November 2014, see here for the Stanford technical paper).
Even more recently Amirhossein Farzmahdi et al. (at the Institute for Research on Fundamental Sciences in Tehran) published a paper on neural-network based face-recognition software (review, for the paper on arXiv see here), derived from studies of primate brains in relation to face recognition. Although still not nearly as good as humans, at least the software shows traits similar to human face-recognition performance.
Holistic face-processing seems to be the human way (`hotly debated yet highly supported’ according to the abstract of the above paper), and neuroscience describes specialized areas in the brain for face recognition.
A conceptual model for human image recognition
Enough background. On to the conceptual model promised in the title. A main question to me in college was:
How can one devise a recognition machinery which does not take up enormous memory?
A key observation seems that although we are good at passive recognition, our active visual memory is very limited. We do not store entire images in our memory. If we are asked to visualize objects, faces, scenes in our mind we will find that it is very hard to really produce `detailed’ mental imagery.
Nonetheless, given some time, we can come up with more and more details. And of course we are extremely good at passive recognition. Even if the face we see has been altered by lighting, aging, facial hair, you name it. But can we always immediately place a name to a face? No we can’t. We often struggle: `… I’m sure I know this person from somewhere, but was it high school? Some holiday? The deli near my previous job? …’
And then slowly, we can enhance our recognition by going down such paths, imagining the person a bit younger perhaps, or with a shovel, or in this deli with an employee’s uniform…until we hit on a strong recognition sense and say: `Hey Nancy, wow, I almost didn’t recognize you with those sunglasses and short hair, it’s been a long time.’
This leads to the following conceptual model. Possibly, our image recognition uses two components: one-dimensional passive recognition and more-dimensional active imagination.
The first component is one-dimensional passive recognition. By this I mean that visual data is generally not stored, but memory-processed in such a way that when similar visual data are observed, a sense of recognition is triggered. One-dimensional: from 0 (no recognition at all) to 1 (sure sense of recognition).
So when we observe say a face, our brain does not store actual `pixels’, but instead creates some sort of tripwire. Or better still: a collection of tripwires. These tripwires then give off a signal when a similar face is observed. The more similarity, the stronger the signal (which produces the sensation: `hey I’ve seen this face before (or close)’).
Then the second component comes into play: more-dimensional active imagination. By this I mean an active imaging, which changes components of the observed image, with the express purpose of amplifying the tripwire signal (the passive recognition sense). Suppose I look at the face before me, imagine it without beard, and the tripwire signal gets stronger… then I am one step closer to recognizing the face. Next I picture this person in my old college, but the signal gets weaker…so next I search in my job history…and I hit a stronger signal upon my third job (still don’t know who it is but I am getting closer)… etc.
In this way, without storing large `files’, it should be possible to reach high levels of passive recognition. This does depend on creating very good tripwires, and having a good active imagination. Such a system would favour `holistic’ recognition (in concurrence with scientific findings), because details are not stored separately.
That’s almost all for now. In the recent news on image recognition software I haven’t seen the idea of `active imaging to enhance passive recognition’ come up (but that doesn’t mean it is not used). Oh, and finally: how does this model explain déjà vu?
Well that is really easy. According to the model, déjà vu occurs when a tripwire is falsely yet strongly triggered. The brain is flooded with a strong sense of recognition, which has no base in a factual previous experience. If you have ever experienced déjà vu, you will likely do so again :-). If it concerns a situation (`I’ve been in this exact situation before’) you could try to see if you can predict what will happen next. According to this model, you can’t, but still the feeling of recognition will only slowly die away.
[Update 17 Feb:]
In this recent article on face detection what I call `tripwire’ is called a `detector’, and a series of tripwires is called a `detector cascade’.
 ΔEntropy.
ΔEntropy.




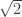 is irrational (which is `rumoured’ to have caused a shock but I cannot find a reliable historical reference for this).
is irrational (which is `rumoured’ to have caused a shock but I cannot find a reliable historical reference for this). ![[0,1]](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D&bg=ffffff&fg=333333&s=0&c=20201002) have Lebesgue measure
have Lebesgue measure  , so we can start constructing
, so we can start constructing 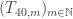 such that
such that  has Lebesgue measure less than
has Lebesgue measure less than  , and such that
, and such that 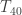 contains all rational numbers in
contains all rational numbers in ![x\in [0,1]](https://s0.wp.com/latex.php?latex=x%5Cin+%5B0%2C1%5D&bg=ffffff&fg=333333&s=0&c=20201002) , I personally don’t think that we will encounter an
, I personally don’t think that we will encounter an 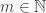 for which we see that
for which we see that 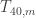 contains
contains  .
. , the basis of the natural logarithm, which equals
, the basis of the natural logarithm, which equals 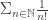 . We can in fact construct
. We can in fact construct 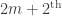 binary approximation to
binary approximation to 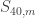 contains
contains 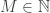 such that (under H1) the probability that
such that (under H1) the probability that 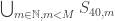 is less than
is less than  we denote the relative Benford chance of drawing
we denote the relative Benford chance of drawing  vs. drawing
vs. drawing  by:
by: 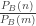 , then we find that
, then we find that 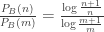 . The relative Zipf chance of drawing
. The relative Zipf chance of drawing 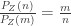 .
. . The important feature of this distribution is twofold:
. The important feature of this distribution is twofold: 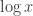 tends to infinity).
tends to infinity).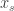 computed by a Turing machine with random number
computed by a Turing machine with random number 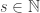 , drawn from some extremely large urn with low entropy (favouring the smaller natural numbers).
, drawn from some extremely large urn with low entropy (favouring the smaller natural numbers). . But all things considered, it seems to me that
. But all things considered, it seems to me that ![[0,1]_{_{\rm REC}}](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D_%7B_%7B%5Crm+REC%7D%7D&bg=ffffff&fg=333333&s=0&c=20201002) the recursive unit interval, that is the set of computable reals in
the recursive unit interval, that is the set of computable reals in 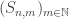 such that the recursive interval
such that the recursive interval 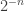 . (see [Bridges&Richman1987] Varieties of Constructive Mathematics Ch. 3, thm. 4.1; the coverings are not constructively measurable because the measure limit cannot be achieved constructively, but this doesn’t affect the probability argument).
. (see [Bridges&Richman1987] Varieties of Constructive Mathematics Ch. 3, thm. 4.1; the coverings are not constructively measurable because the measure limit cannot be achieved constructively, but this doesn’t affect the probability argument).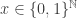 , we can see
, we can see  denote the standard Lebesgue measure, and let
denote the standard Lebesgue measure, and let ![A\subseteq [0,1]](https://s0.wp.com/latex.php?latex=A%5Csubseteq+%5B0%2C1%5D&bg=ffffff&fg=333333&s=0&c=20201002) be Lebesgue measurable. Then in classical probability theory the probability that
be Lebesgue measurable. Then in classical probability theory the probability that  equals
equals 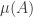 . (Assuming the coin is `fair’ which leads to a uniform probability distribution on
. (Assuming the coin is `fair’ which leads to a uniform probability distribution on  be
be 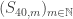 . Notice that
. Notice that 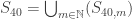 has Lebesgue measure less than
has Lebesgue measure less than  , and the uniform probability distribution applies for a coin-flip-randomly produced real in
, and the uniform probability distribution applies for a coin-flip-randomly produced real in  is less than
is less than  is in the interval
is in the interval 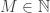 such that with probability less than
such that with probability less than 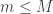 ?
?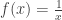 cause (the integral diverges) and offers exactly the same solution: look at relative probabilities of events, instead of absolute probabilities. To top it off, Tarantola emphasizes that the measure density function
cause (the integral diverges) and offers exactly the same solution: look at relative probabilities of events, instead of absolute probabilities. To top it off, Tarantola emphasizes that the measure density function  .
.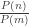 seems new [except it isn’t, see the next post], and it does yield Benford’s law. The entropy-related motivation for these relative chances also seems to be new. The (relative) chances involved in drawing a natural number at random will play a role in the discussion to come (on Laplacian determinism, digital physics and foundations of probability theory). But first let us explicitly derive Benford’s law from these chances:
seems new [except it isn’t, see the next post], and it does yield Benford’s law. The entropy-related motivation for these relative chances also seems to be new. The (relative) chances involved in drawing a natural number at random will play a role in the discussion to come (on Laplacian determinism, digital physics and foundations of probability theory). But first let us explicitly derive Benford’s law from these chances: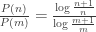
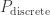 can perhaps be formulated, yielding: for
can perhaps be formulated, yielding: for 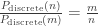 .)
.) in base 10 (the argument is base-independent though) to be drawn at random according to our entropy-related chances. We then see that the relative chance of drawing a 1 compared to drawing a 2 equals
in base 10 (the argument is base-independent though) to be drawn at random according to our entropy-related chances. We then see that the relative chance of drawing a 1 compared to drawing a 2 equals  which in turn equals
which in turn equals  . Since the sum of the probabilities of drawing 1, 2,…,9 equals 1, one finds that the chance of drawing
. Since the sum of the probabilities of drawing 1, 2,…,9 equals 1, one finds that the chance of drawing  as first digit for
as first digit for 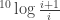 .
.